mysql
网络爬虫
最短路
Aerospike
数据类型
rtmp
计算机毕业设计选题
delete
junit5
激光测距传感器
activity7
ps
MMoE
重构
ATM系统
汇编求解一元二次方程的解
abaqus
测评补单
taro
pillow
WebMagic
2024/4/16 6:09:41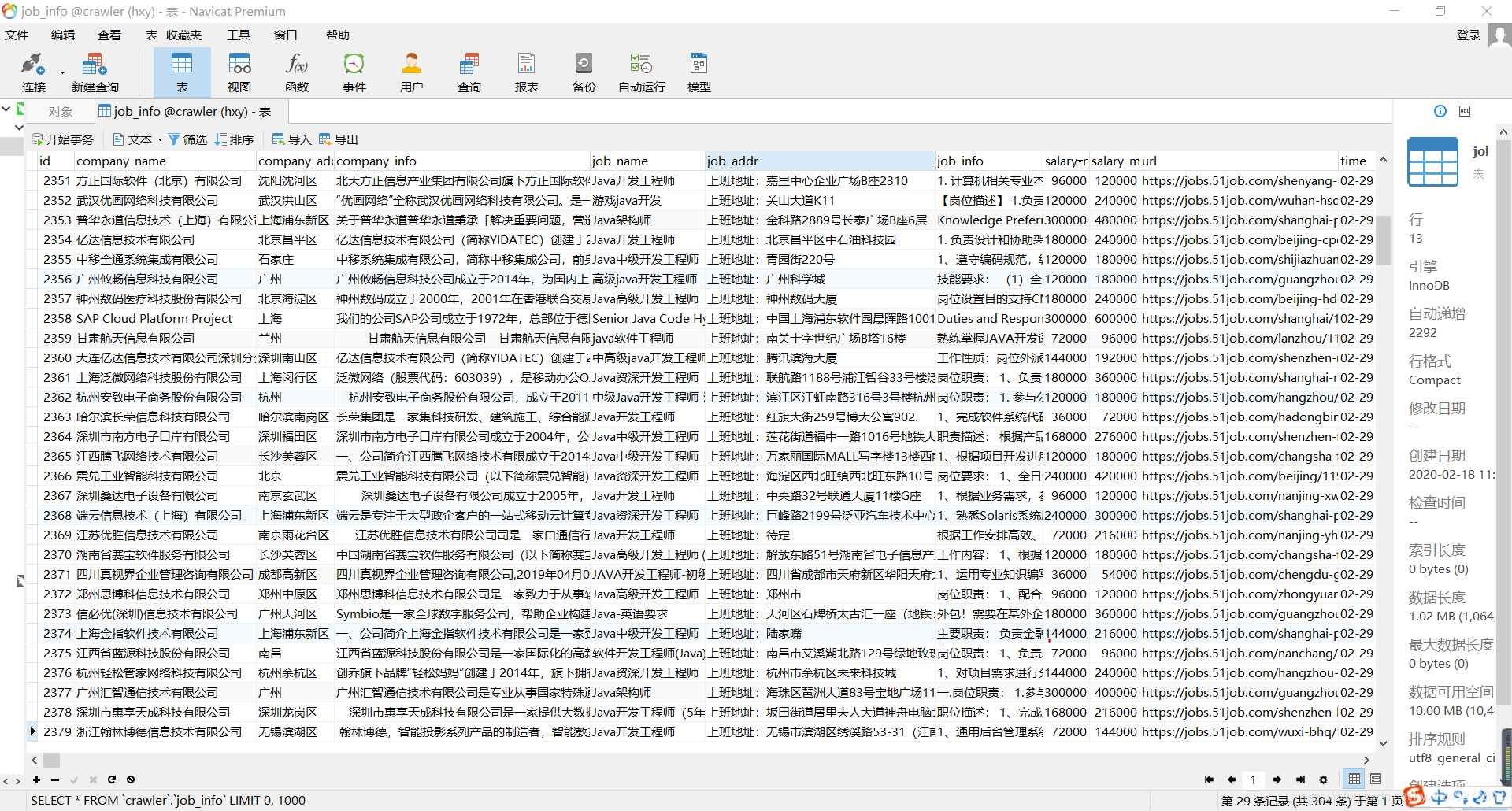
Java 爬取 51job 数据 WebMagic实现
Java 爬取 51job 数据
一、项目Maven环境配置
相关依赖 jar 包配置
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.0.2.RELEASE</version>
</parent&g…
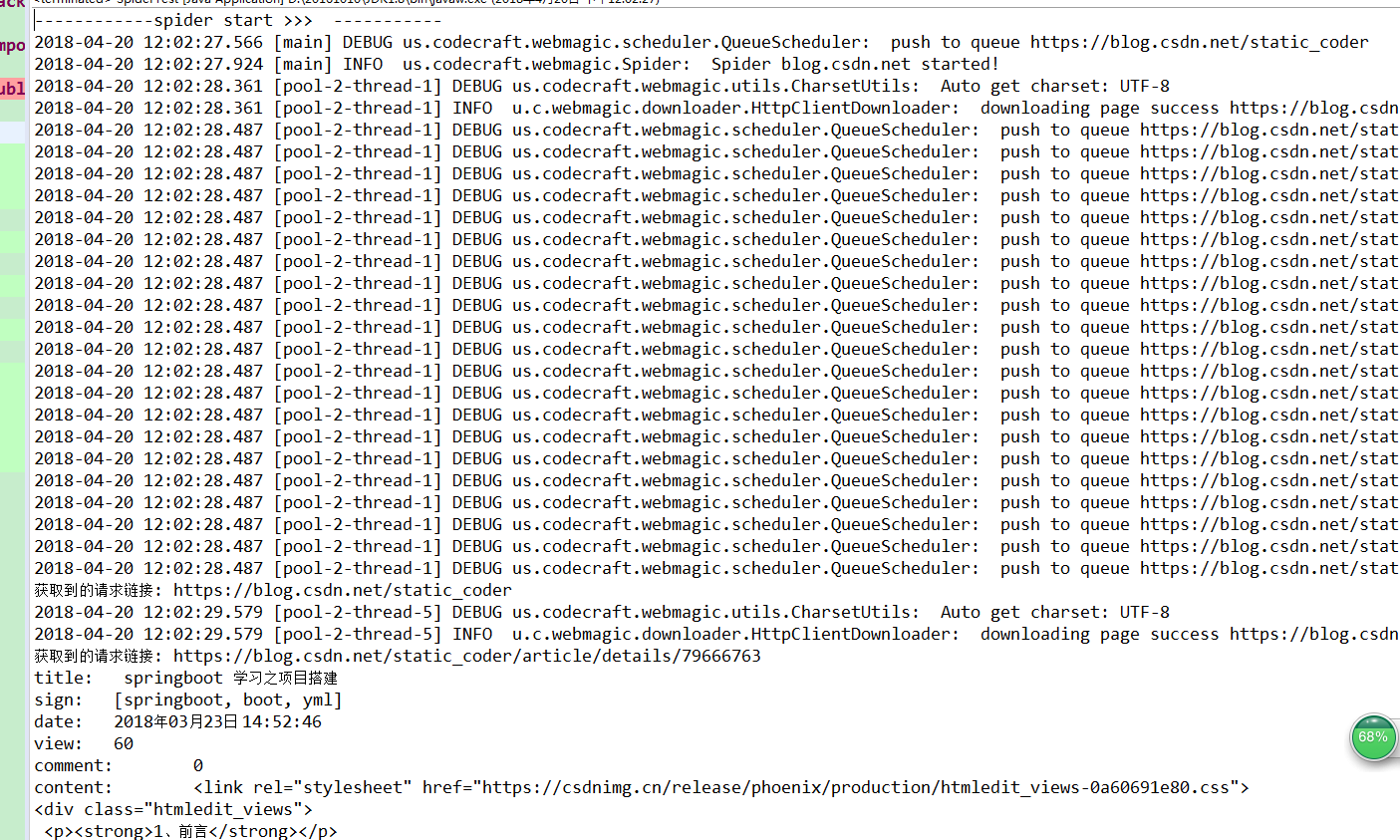
基于webmagic爬虫的简单编写
1、前言
前一段时间修改了一个项目的功能,项目基于webmagic编写的爬虫。于是开始一些学习。现在整理整理(该项目基本笔者的csdn博客的爬取为例),算是从小白到入门吧。之前使用httpclient和jsoup玩过一点点,但是感觉好麻…

WebMagic抓取医院科室,医生信息实战及踩坑
简介
WebMagic项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。WebMagic的架构设计参照了Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。 WebMagic概…

使用WebMagic 编写 java 网络爬虫
写这个的目的是为了爬歌词,因为喜欢听歌,遇到喜欢的歌就喜欢把歌词下载下来。 WebMacgic 教程地址
http://webmagic.io/docs/zh/posts/ch1-overview/ 使用 IDEA 创建 maven工程 下面为工程目录结构 下面为源代码 package bean;import us.codecraft.webm…

webmagic结合seimiagent实现动态信息页面的采集
webmagic结合seimiagent实现动态信息页面的采集
简介
webmagic是一个非常流行的已api方式采集网页信息的项目,但是对于动态加载的信息不能很好的支持,而目前大多数网页都或多或少的采用了动态加载方式展示页面信息。
目前webmagic已经有了一个解决方案…
WebMagic 爬虫技术
WebMagic
WebMagic 介绍
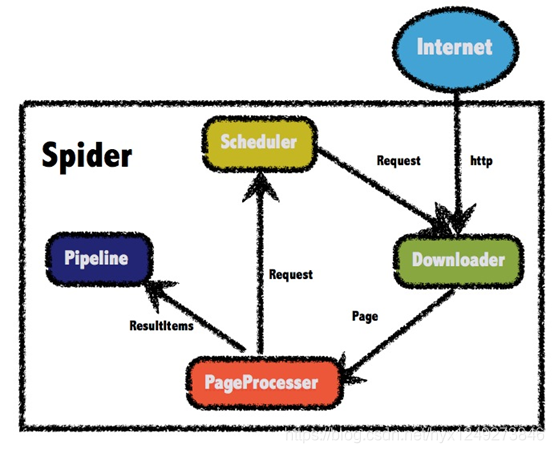
WebMagic基础架构
Webmagic 的结构分为 Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由 Spider将他们彼此组织起来。这四种组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。Spider将这几个组件组织起来…

使用WebMagic爬虫框架爬取暴走漫画
WebMagic是黄亿华先生开发的一款java轻量级爬虫框架。我之所以选择WebMagic,因为它非常轻量级,可以学习爬虫的原理,而且用WebMagic非常容易进行功能扩展。也许你会听过另一个爬虫框架,Heritrix。博主一开始也是先入手了Heritrix&a…
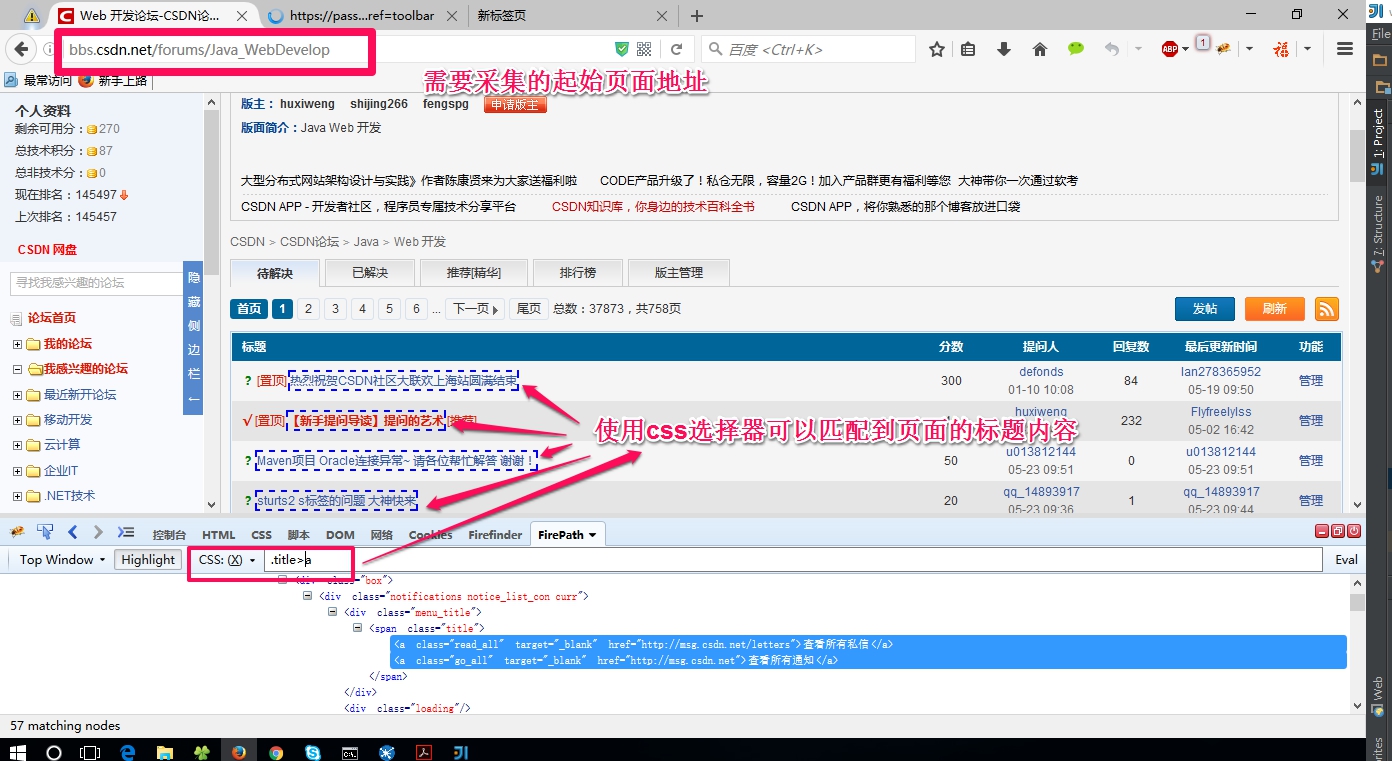
webmagic采集CSDN的Java_WebDevelop页面
项目中使用到了webmagic,采集论坛一类的页面时需要一些特殊的配置。在此记录一下 先来看看我要采集的页面 点击第2页可以看到它的url是http://bbs.csdn.net/forums/Java_WebDevelop?page2
点击尾页可以看到它的url是http://bbs.csdn.net/forums/Java_WebDevelop?…